
Softwaretests: Verwendung großer Sprachmodelle, um den Fall vor den Sicherheitsanforderungen zu speichern
Die Überprüfung und Validierung der Softwarekomponenten basiert auf breiten Tests. Die zum Testen der Tests erforderlichen Tests stammen aus den angegebenen Anforderungen, anschließend die Ergebnisse, und die Ergebnisse werden mit den Adoptionskriterien für die Testfälle verglichen. Selbst für relativ kleine Systeme ist die Ableitung von Testfällen intensive Ressourcen, daher ist es ein teurer Aufwand. Unter der Annahme einer konservativen Schätzung von 5-10 Minuten pro Test benötigen mehr als zwanzig Menschen 500 Anforderungen für Schreibsystem-Testfälle. Wir können die Wirksamkeit der Erstellung von Testfällen erhöhen.
Die Entwicklung komplexer Systeme beginnt mit den Spezifikationen ihrer Anforderungen. Für zuverlässige Systeme und Sicherheitssysteme sind auch Sicherheitsanforderungen auf der Grundlage der Systemsicherheitsanalyse enthalten. Die manuelle Erwerbe für Testfälle kostet viel Zeit für diese Anforderungen. Wenn wir jedoch LLMs nutzen, können wir diesen Prozess jedoch verbessern. Als LLM -Eintrag wird die Darstellung des Textes der Begriffe verwendet, und dann werden die Undefinitionen und Szenarien im gemeinsamen Textformat oder in den formalen Spezifikationen, beispielsweise die Spezifikation des ASAM Open -Tests, transformiert. Der aktuelle Test des Testingenieurs -Testfälle von Tests kann die Integrität und Korrektheit dieser Testfälle sicherstellen. Unter Verwendung von LLMs kann der Testingenieur durch Formulierung von Testfällen und Überprüfung und Raffinesse von Testfällen sowie automatisch abgeleitete Testfälle und Szenarien reduziert werden.
Die Verwendung von großsprachigen Modellen kann die Zeit und die Kosten, die für die Erstellung von Testfällen erforderlich sind, erheblich verkürzt.
LLM-basierter Testfallgenerator
Wir haben einen LLM-basierten Testgenerator entwickelt und den Fall angewendet, um “Lane Keep Help” zu verwenden. LLMs können eigene Zweifel und Qualitätsdefizite haben. Unsere grundlegende Architektur bewertet Qualität und Unsicherheit. Die folgende Tabelle zeigt eine Zusammenfassung der grundlegenden Anforderungen für das ausgewählte Szenario, und das Bild zeigt den Prozess von Testfällen unter Verwendung unserer LLM-basierten Ansicht.
| Bedingung ID | Bedingung ID Reqif | Kategorie | Begriffe Beschreibung |
|---|---|---|---|
| 1.1 | R001 | Spur erkennen | Das System muss mit Kameras und / oder Sensoren Fahrspurmarken auf der Straße erkennen. |
| 1.2 | R002 | Spur erkennen | Das System identifiziert die Grenzen der Spur gemäß unterschiedlichen Beleuchtungs- und Wetterbedingungen. |
| 2.1 | R003 | Erinnerung der Fahrspurverlassene | Das System warnt den Fahrer, wenn das Fahrzeug unbeabsichtigt ist, wenn sie die Fahrspur verlassen. |
| 2.2 | R004 | Erinnerung der Fahrspurverlassene | Die Warnung wird durch die Sichtweise von visuell, auditorisch und / oder Haptik bereitgestellt. |
| 3.1 | R005 | Scand | Das System fährt langsam zum Fahrzeug, das auf die Fahrspur zurückkehrt, wenn es die unerwünschte Ausgabe erkennt. |
Posteingangsanforderungen können im Format von REQIF, JSON oder CSV bereitgestellt werden. LLM wird verwendet, um Testfälle basierend auf den angegebenen Anforderungen zu erstellen. Daten innerhalb der Anforderungen können vertraulich sein. Wir haben unser internes LLM -Tool verwendet, das die Informationen nicht erklärt.
Anforderungen und Testfälle zur Aufrechterhaltung der Vertraulichkeit, die intern erweiterte LLM -Modelle verwendet werden.
Schaffung automatischer Testfälle
Großsprachige Modelle erstellen ihren Ausgang basierend auf Fragen. Um Testfälle zu erstellen, kann es mit einem einfachen Fragebogen beginnen, z. B. “Erstellen Sie einen Testfall für die folgende Bedingung”. Dies gibt Ihnen jedoch nicht das gewünschte Ergebnis. Untersuchungen haben gezeigt, dass LLMs so weit wie möglich leichter arbeiten. Unter Verwendung von ISO 26262 -Vorschriften befanden wir uns im Fragebogen, der die angegebenen Ausgangsmerkmale und die Testfallspezifikationsattribute bestimmt.
Qualitätsbewertung
Wenn wir Testfälle mit LLMs erhalten, ist es wichtig, ihre Qualität automatisch zu bewerten. Obwohl wir von einem Testingenieur Testfälle bewertet haben, können wir sie vor der Beurteilung der Qualität verwenden und somit die vom Testingenieur für die Bewertung erforderliche Zeit verringern. Oder aktivieren Sie die neue Generation des entsprechenden Testfalls, wenn Qualitätsfehler erkannt werden.
Wir befanden uns in einer Bewertung, die auf Qualitätsbewertung, Verfügbarkeit und Fairness inhaltlich beruhte. Aus den Regeln (ISO 26262, ISO 29119 usw.) haben wir die für Testfälle erforderlichen Attribute extrahiert. Anschließend haben wir jeden Testfall bewertet, um festzustellen, ob die erforderlichen Attribute oder fehlt. Basierend darauf bewerteten wir die Integrität des Inhalts mit einfachen und zusammengesetzten Maßnahmen, wie nachstehend beschrieben.
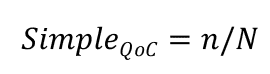
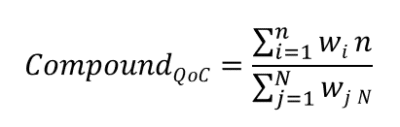
Die Richtigkeit der erstellten Tests kann anhand der angeforderten Kriterien bewertet werden. Dies kann manuell oder automatisiert gemacht werden. Für die manuelle Bewertung werden die in Standards festgelegten Kriterien wie ISO 26262 und ISO 29119 verwendet. Die folgende Tabelle erscheint einige dieser Kriterien.
| Sl Nr | Obpiria | Glücklich Ja / Nein | Kommentar |
|---|---|---|---|
| 1 | Die Sprache ist einfach und korrekt | ||
| 2 | Schritte sind genau und genau | ||
| 3 | Schritte sind Lichter und Zweifel | ||
| 4 | Gebrauchtes Terminologie und konsistentes Format | ||
| Nur | Einträge sind klar definiert |
Einfache Inhaltsqualität (QOC) und QOC -Verbindungsmetrik sowie die Richtigkeitskriterien können verwendet werden, um die Qualität der erstellten Tests zu bewerten. Dies kann auch in Fällen automatisiert werden, die in Fällen von Tests von Menschen (tatsächliche Testfälle) verfügbar sind. Diese Testfälle können verwendet werden, um die Korrektheit unter Verwendung der kombinierten Zeichenfolgen mithilfe von Techniken zu bewerten. Es kann jedoch durch ausgefeiltere Techniken ersetzt werden oder auf LLMs basieren.
Unsicherheitsbewertung
LLMs reduziert den Bereich der Verarbeitung natürlicher Sprache erheblich, sie stehen immer noch Herausforderungen im Zusammenhang mit der Unsicherheit. Wir haben die Unsicherheit von fünf LLM -Modellen bewertet, die sich auf die Hausaufgaben konzentrierten. Die fünf bewerteten Modelle sind: Pixtral-12b, Lama2, Lama3.1 (8B & 70b) und Gemma: 27B. Bewertung von Unsicherheitsdaten wie GSM 8 (Bewertung der Fähigkeit zur Lösung von arithmetischen und algebraischen Denken, Geschäftsethik (MML -Datensatz in geschäftlichen Kontexten MML -Datensatz) und professionell ). 4. Zeigt die Ergebnisse im Bild an.
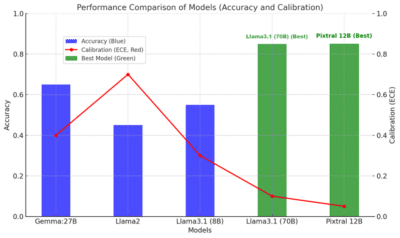
Aus allen bewerteten Modellen fanden sie das beste Lama3.1 (70B) und das Pixtral -Spiel.
Schlussfolgerung von Softwaretests
In dieser Arbeit haben wir die Methode zum Erstellen von Testfällen mit LLMs eingegeben. Wir haben Maßnahmen bewertet, um die Qualität der Tests zu bewerten und die Unsicherheit von LLM zu bewerten. Als nächster Schritt planen wir, die Übersetzung von Testfällen im ASAM Open -Testformat zu automatisieren und auszuführen.
Referenzen
- ISO 26262 Straßenfahrzeuge – Funktionelle Sicherheit
- ISO 29119 Software- und Systemtechnik – Softwaretests
-
Agrowal, Pravesh und Al. X pixtral 12b. ” Arxiv Preprint Arxiv: 2410.07073 (2024).
-
Touvron, Hugo und Al. “Lama 2: Open Foundation und Tuned Chat -Modelle.” Arxiv Preprint Arxiv: 2307.09288 (2023).
-
Dubey, Abhimanyu et al. “Die Herde von Lama 3 Models.” Arxiv Preprint Arxiv: 2407.21783 (2024).
-
Gruppe, Gemma und Al. “Gemma 2: Verbesserung der offenen Sprachmodelle in praktischer Größe.” Arxiv Preprint Arxiv: 2408.00118 (2024).
-
Cobbe, Karl und “Trainingsprüfer, um die Wörter der Mathematik zu reparieren”. Arxiv Preprint Arxiv: 2110.14168 (2021).
-
Hendrycks, Dan et al. “Messung der Multitasking -Sprache. (MMLU)” Arxiv Preprint Arxiv: 2009.03300 (2020).
Related Posts

Microsoft AutoAdminLogon knacken und Admin Center rückgängig machen (27. Juli 2026) Borns IT- und Windows-Blog

Batteriehersteller Varta reicht mehrere Insolvenzanträge ein (24. Juli 2026) Borns IT- und Windows-Blog
