
Simplifying Simulation Scenario Design and Execution: A Guide to Creating and Configuring FERAL Simulation Scenarios with YAML
Introduction
Creating and configuring simulation scenarios is effort-intensive and time-consuming, mainly because each scenario requires a unique set of configurations, parameters, and settings, making the procedure time-consuming and error-prone. This complexity not only reduces productivity but also increases the learning curve for simulation specifiers and designers.
What if there was a way to streamline this process, making simulation specification and configuration as straightforward as editing a simple text file?
For that, we have a straightforward solution: a YAML file that describes the scenario without having to write a single line of a program statement. By leveraging YAML for simulation specification and configuration, we introduce a technique that simplifies the initial simulation configuration and adjustments of simulation parameters.
The objective of this blog post is to examine the approach and solution in depth, providing simulation designers and specifiers with a step-by-step guide, the challenges this approach tackles, and the solutions it offers. From experienced developers looking to boost productivity to newbies interested in simulation specification and configuration, this guide will provide the information and tools needed to set up their simulation in FERAL.
The challenge of simulation configuration
We have identified the following challenges regarding the design and configuration of simulations:
Complexity and Time Consumption
One of the primary challenges in simulation scenario creation and configuration is its inherent complexity [7]. Developers must specify numerous parameters, from environmental variables and entity behaviors to interaction rules and initial conditions [3, 5]. For example, environmental parameters such as temperature must be carefully set to match real-world conditions for a climate model, affecting weather patterns and ecosystem responses. Similarly, in urban simulations, traffic flow parameters must reflect peak and off-peak conditions to study congestion and optimize traffic signals accurately. In healthcare simulations, parameters like disease spread rates and patient immune responses must be accurately modeled to predict outcomes under various public health interventions. Furthermore, in automotive bus system simulations, the meticulous setting of parameters such as signal propagation time and bus load percentage is crucial for the evaluation of system performance in high-traffic scenarios. Also, fault injection rates and response times are critical parameters that must be precisely defined to assess the robustness of the bus system against potential errors or failures. The requirement to manually program these simulation models and their associated parameter configurations, which frequently necessitates a thorough understanding of the simulation framework’s architecture and syntax [4, 8], further complicates these issues. For instance, consider the challenge of learning and applying C++ to develop a simulation for a CAN bus system using the ns-3 network simulator. This task demands not only a grasp of basic programming knowledge of C++ but also a deep understanding of both the ns-3 architecture and the specific protocols and behaviors of the CAN network. As a result, the modeling and configuration process takes longer, slowing down the development cycle and causing testing and deployment delays.
Error-Prone Processes
Manual configuration is also prone to errors [1]. A misplaced comma, an incorrect value, or an improperly defined entity can lead to simulation errors that are difficult to diagnose and correct. These errors can significantly impact a simulation’s validity, leading to inaccurate results or, in the worst-case scenario, complete simulation failure.
Accessibility for New Users
For newcomers, the steep learning curve associated with understanding both the simulation framework and the syntax for its specification and configuration can be daunting. This can deter potential users and limit the diversity of perspectives and expertise in the simulation development community.
The Need for a Solution
Given these challenges, there is a clear need for a solution that simplifies the simulation specification and configuration process [6], making it more accessible, efficient, and error-free. Such a solution would not only accelerate the development cycle but also enhance the quality and reliability of simulation outcomes. In this context, YAML exhibits potential as an exciting new approach to simulation specification and configuration when paired with smart tooling.
Choosing YAML for configuration
Human-Readable Format
YAML’s design prioritizes human readability and ease of understanding. Its syntax is intuitive, making it accessible even to those new to simulation development. In contrast to alternative data serialization formats that may present challenges in terms of understandability and readability for human users, YAML’s well-defined structure enables users to effortlessly define complex scenarios and configurations without getting lost in syntactic complexities. This readability significantly reduces the learning curve for new users and decreases the likelihood of errors in configuration files.
Below is a simple example of a YAML file that configures a basic web server environment with a description for each key.
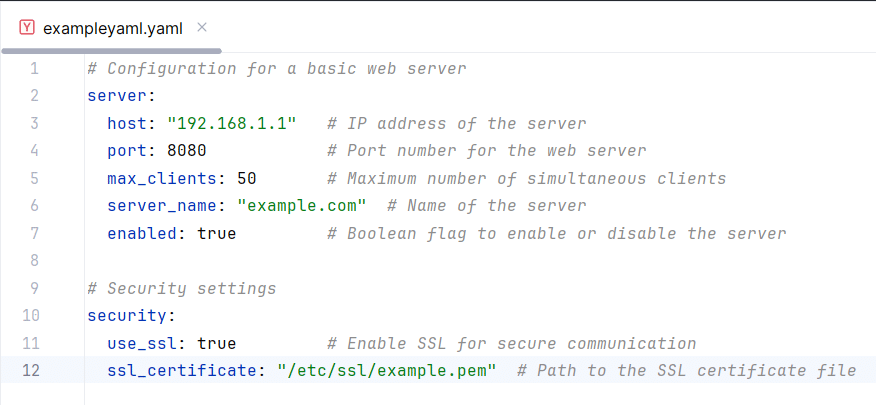
Figure 1: An example YAML file
The above YAML illustrates a configuration for a basic web server, segmented into two primary sections: server and security. In the „server“ section, details such as the server’s IP address, port number, maximum number of clients it can manage simultaneously, the server’s name, and whether the server is active are specified. Each setting is clearly labeled by a key, such as `host`, `port`, or `enabled`, followed by the corresponding value. Comments introduced with the `#` symbol explain the purpose of each setting, enhancing clarity and ease of use. The „security“ section outlines security-related settings, specifying whether SSL is enabled for secure communication and the location of the SSL certificate file. This structure, with keys followed by values and supplemented by descriptive comments, makes the YAML file straightforward and easy to maintain, demonstrating why YAML is favored for configuration files.
Hierarchical Structure
Simulations often involve nested configurations, where entities are defined with various attributes that may also contain their configurations. YAML naturally supports hierarchical data representation, making it an excellent fit for defining the multi-layered settings of simulations. This feature allows developers to organize configurations in a way that mirrors the logical structure of the simulation, enhancing clarity and maintainability.
Facilitating Collaboration and Standardization
YAML’s simplicity and readability extend beyond individual developers to teams and communities. It promotes collaboration by making configurations simple for all team members to share, review, and comprehend, regardless of their position or level of expertise. Furthermore, the use of YAML encourages standardization of configuration files across projects, promoting best practices and consistency in simulation development.
Bridging the Gap for Simulation Model Designers
For designers of simulation models, YAML provides a flexible and straightforward means to develop configurable models. By defining model parameters and behaviors in YAML, designers can create templates that users can easily customize, lowering the barrier to entry for utilizing advanced simulations and enabling a wider range of applications.
Enhancing YAML with intelligent tooling for simulation in FERAL
The choice of YAML for simulation configuration brings numerous benefits, but when paired with intelligent tooling, its potential is fully unlocked. This section explores how tools like IntelliJ IDEA by JetBrains or Visual Studio Code by Microsoft integrated with the RedHat YAML plugin for Visual Studio Code and the SnakeYAML parser enhance the YAML experience, making simulation configuration more efficient, error-resistant, and user-friendly. In this regard, we have developed a simulation specification and configuration environment for the simulation framework FERAL (Framework for Evaluation on Requirements and Architecture Level) [2]. The integration of these technologies with FERAL offers auto-completion, validation, and direct feedback within the IDE, resulting in a notable decrease in the potential for errors and an expedited configuration procedure.
Intelligent Code Completion and Validation
One of the most significant advantages of using intelligent tooling with YAML is the support for intelligent code completion and validation. These features guide users through the creation of configuration files, suggesting possible completions and flagging errors in real-time. This not only accelerates the development process but also minimizes the risk of misconfigurations that could lead to simulation failures.
Auto-Completion
With auto-completion, simulation specifiers and designers no longer need to memorize the exact structure of the configuration files, or the specific attributes required for each simulation component. The tooling suggests the available options as they type, based on the context and the schema of the simulation configuration. This feature is particularly beneficial for complex simulations with numerous parameters, reducing the cognitive load on the specifier and ensuring that all necessary configurations are accurately specified.
Real-Time Validation
Real-time validation continuously checks the YAML file against the defined schema, immediately highlighting any discrepancies, such as missing required fields, incorrect data types, or values out of the allowed range. This instant feedback allows developers to correct issues on the fly, long before the simulation is run, thereby avoiding time-consuming debugging sessions.
Simplifying Complex Configurations
Simulations often involve complex setups with nested configurations and dependencies between components. Intelligent tooling simplifies the management of these complex configurations by providing a clear and interactive interface. Developers can easily navigate through the layers of the configuration, understand the relationships between components, and make changes with confidence, knowing that the tooling will alert them to any inconsistencies.
Documentation and Learning Support
Intelligent tooling often includes integrated documentation and tool tips, offering instant access to information about the configuration options and their implications. This embedded guidance is invaluable for learning and reference, enabling developers to understand the full capabilities of the simulation software without constantly referring to external documentation.
Facilitating Collaboration and Standardization
By leveraging intelligent tooling, teams can ensure consistency and standardization across their simulation projects. The tooling can enforce predefined schemas and configuration standards, making it easier for team members to collaborate effectively, share configuration templates, and maintain an elevated level of quality and reliability in their simulations.
Step-by-step guide for configuring a simulation in FERAL
Configuring a simulation in FERAL is designed to be a straightforward process, thanks to its YAML-based configuration system and the support of intelligent tooling. This guide will walk you through the steps to configure a simulation scenario in FERAL using IntelliJ IDEA and the FERAL schema for validation.
Step 1: Setting Up Your Environment
Before you begin, ensure that you have the FERAL jar file added to your project in IntelliJ IDEA. This jar file contains the necessary libraries and dependencies to run FERAL simulations. Additionally, if you have not done so already, install the Red Hat YAML plugin if you are using VS Code, or use IntelliJ IDEA, which does not require any additional plugin. These IDEs provide enhanced YAML editing experience with features like auto-completion and real-time validation. In IntelliJ IDEA, the setup looks like below:
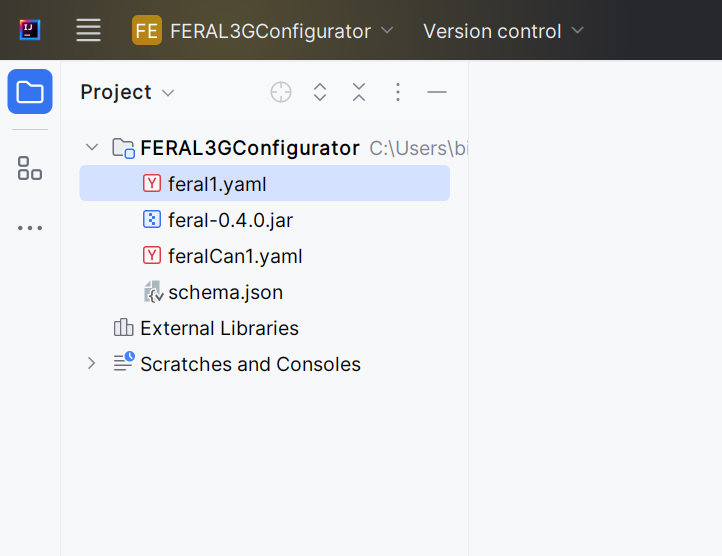
Figure 2: FERAL 3GP configuration setup in IntelliJ IDEA
Step 2: Creating Your YAML Configuration File
Start by creating a new file with a .yaml extension in your project directory (feral1.yaml file in Figure 2). This file will contain the configuration for your simulation scenario. The structure of the file will define various aspects of the simulation, such as the components involved, their configurations, and the interactions between them.
Step 3: Writing Your Simulation Scenario
With your environment set up and your YAML file ready, you can start defining your simulation scenario. As you type, VS Code or IntelliJ IDEA and the FERAL schema will offer auto-completion suggestions and highlight any errors or inconsistencies in real-time. This immediate feedback allows you to correct issues as they arise, ensuring your configuration aligns with. Figure 3 depicts an example simulation specified in YAML to simulate a CAN BUS network.
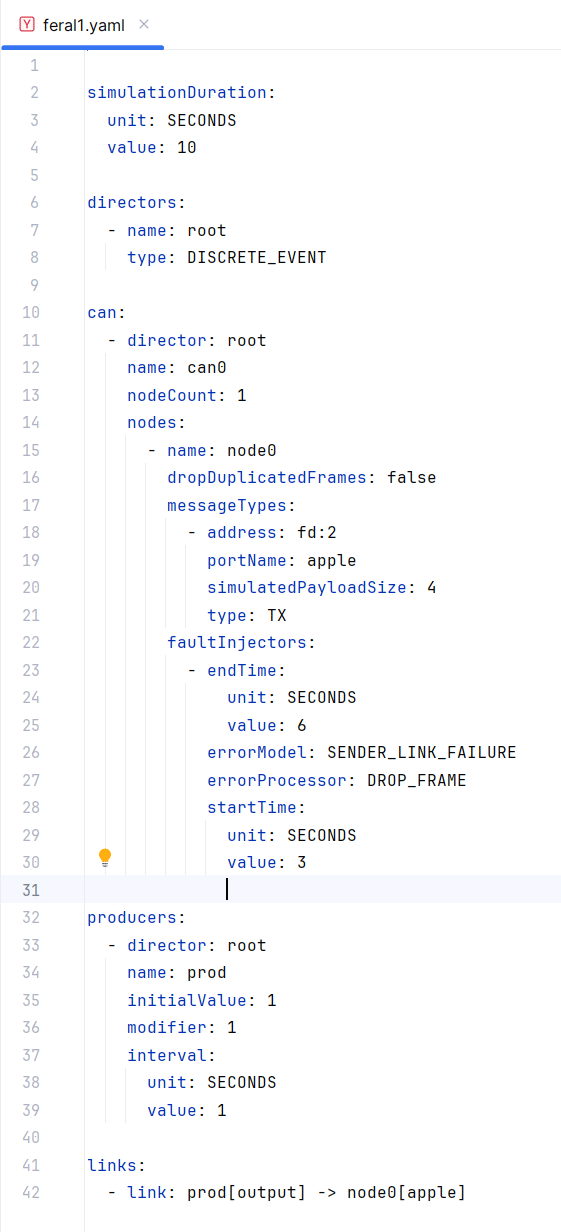
Figure 3: A simple CAN bus network simulation specification in FERAL
Auto-Completion: As you begin typing in the YAML file, the IDE will suggest possible keys (parameters of the FERAL simulation) based on the schema. This feature is incredibly helpful for discovering the configuration options available in FERAL and ensuring you are using valid parameters. Figure 4 depicts how the auto-completion looks like in IntelliJ IDEA.
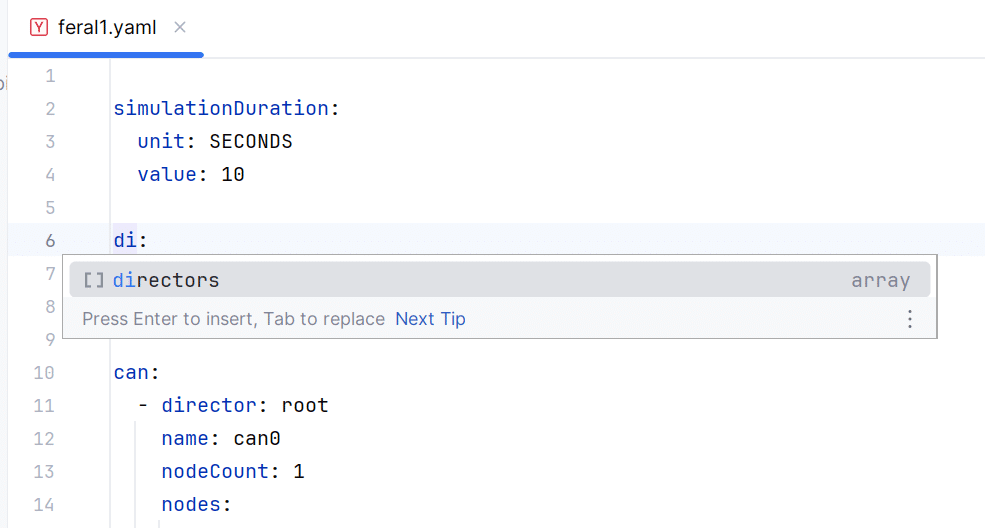
Figure 4: FERAL auto-completion in simulation scenario specification
Validation and Error Reporting: If there are any discrepancies in your configuration, such as missing required components or incorrect value types, VS Code or IntelliJ IDEA will underline those errors (Figure 5). Hovering over the errors will provide a detailed description of the issue and possible solutions, guiding you towards a valid simulation configuration.
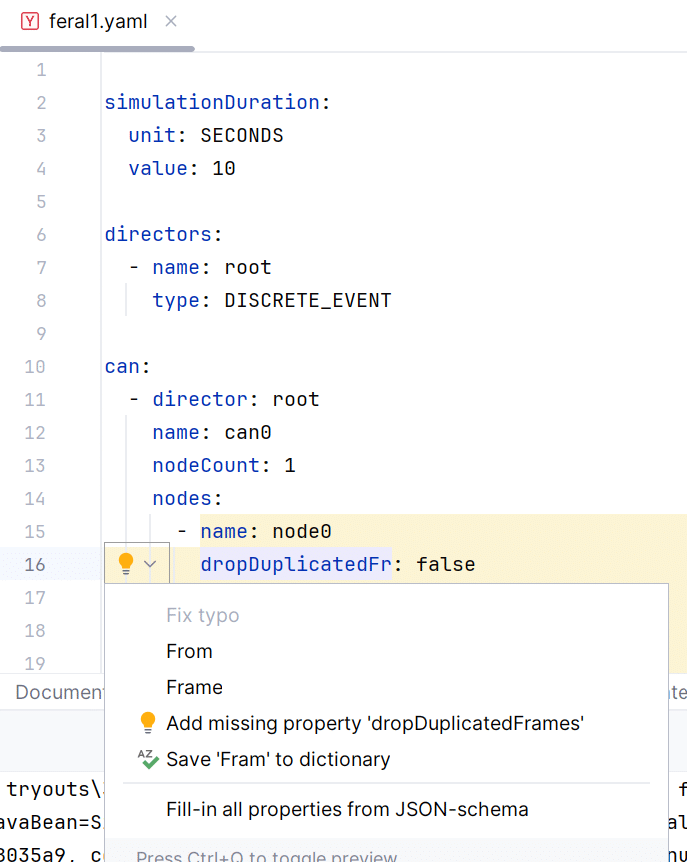
Figure 5: FERAL simulation scenario validation checks in YAML
Step 4: Running Your Simulation
Once your YAML configuration file is complete and free of errors, you are ready to run your simulation. FERAL provides the following command to execute the simulation:
java -jar feral-0.4.0.jar –yaml feral1.yaml
and allows checking the results of the scenario in the console of the IDE.
This step-by-step guide simplifies the process of configuring simulations in FERAL, making it accessible to users with varying levels of programming expertise. By leveraging the power of YAML and intelligent tooling, FERAL democratizes simulation design, allowing more users to participate in the creation and analysis of embedded system simulations.
Use case: A real-world example with FERAL
In this section, we will explore a practical example of configuring a CAN bus simulation using FERAL. This scenario demonstrates how FERAL’s YAML-based configuration allows for the detailed specification of simulation parameters, including the simulation environment, network components, and fault conditions. The goal is to simulate a network with a single CAN node (can0) that experiences a link failure, affecting message transmission for a specified duration.
Scenario Overview
Here we will consider the simulation scenario defined in Figure 3. The scenario is designed to run for 10 seconds, during which a producer (prod) generates messages at a regular interval of 1 second. These messages are intended for node0 on the CAN bus (can0). However, a fault injector is configured to simulate a sender link failure between seconds 3 and 6, resulting in dropped frames during this period.
Configuration Breakdown
Simulation Duration: The simulation is set to be executed for 10 seconds, providing a concise window to observe the fault injection’s impact.
Directors: A single director named root is defined with a DISCRETE_EVENT type, orchestrating the simulation’s event-driven behavior.
CAN Configuration: The CAN network configuration specifies one node (node0) under the can0 network, managed by the root director. This node is configured not to drop duplicate frames, allowing for a straightforward analysis of the fault injector’s effect.
Fault Injectors: node0 is equipped with a fault injector configured to simulate a sender link failure (SENDER_LINK_FAILURE) by dropping frames (DROP_FRAME) from seconds 3 to 6 of the simulation. This setup provides a clear example of how network faults can be simulated and studied within FERAL.
Producers: A producer named prod is defined to generate messages with an initial value of 1, which is incremented by 1 at each interval of 1 second. This producer is linked to node0, simulating a data source for the node.
Links: The configuration establishes a link between the producer’s output and node0’s input port named apple, facilitating the flow of messages into the CAN network.
Executing the Simulation
To execute this simulation, users can simply create a YAML file (as in Figure 3) and utilize FERAL’s simulation execution command described in Step 4 of the previous section. As the simulation progresses, users can check the result in the console of the IDE (Figure 6), observe the normal operation of message transmission, the effect of the fault injector during the specified interval (if any), and the resumption of normal operation after the fault condition ends.
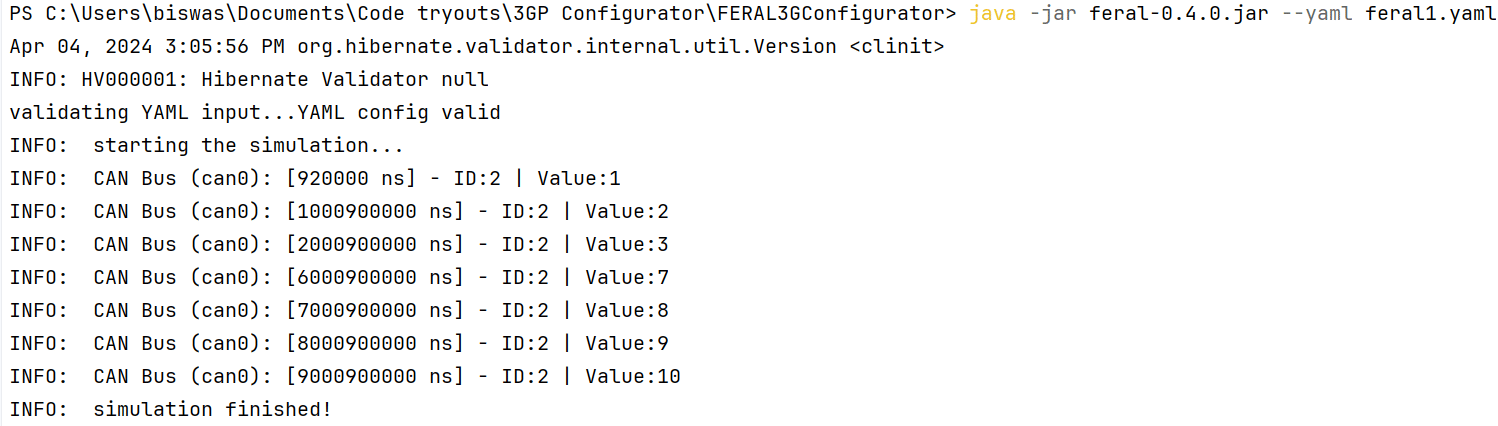
Figure 6: Execution result of FERAL CAN bus network simulation
This use case exemplifies the power and flexibility of FERAL for simulating complex embedded systems and their behaviors under various conditions. By leveraging YAML for configuration, FERAL makes it possible to design, execute, and analyze simulations without deep programming knowledge, opening the field of embedded system simulation to a broader audience.
Conclusion
The journey from conceptualizing a simulation scenario to its successful execution involves numerous steps, each with its own set of challenges and complexities. By adopting YAML for simulation configuration, we significantly streamline this process, making it more accessible, efficient, and error-resistant. YAML’s human-readable format, combined with the power of intelligent tooling like the Red Hat YAML plugin for VS Code, transforms the way simulations are designed and executed.
This approach not only simplifies simulation design, allowing individuals without deep programming expertise to configure and run complex simulations, but also enhances collaboration among team members. With the ability to validate configurations on the fly, designers can catch and correct errors early in the development process, saving time and resources that would otherwise be spent debugging simulations post-execution.
Moreover, the adoption of best practices in YAML configuration ensures that simulations are not only correctly set up but also optimized for performance and maintainability. By organizing and documenting simulation configurations effectively, teams can build a robust library of scenarios that can be reused and adapted for future projects, further accelerating the simulation development cycle.
In conclusion, the incorporation of YAML configurations into simulation environments like FERAL, along with intelligent IDE tooling and adherence to best practices, represents a significant advancement in simulation technology. It empowers engineers, researchers, and educators to more easily harness the power of simulations to explore, validate, and demonstrate complex systems and phenomena. As we continue to evolve these tools and practices, the potential for innovation in simulation-driven fields is boundless, promising ever more sophisticated and insightful outcomes.
References
- Hoseini, S., Hamou-Lhadj, A., Desrosiers, P., & Tapp, M. (05312014). Software feature location in practice: debugging aircraft simulation systems. In P. Jalote, L. Briand, & A. van der Hoek (Eds.), ICSE ’14: 36th International Conference on Software Engineering, Hyderabad India, 31 05 2014 07 06 2014 (pp. 225–234). New York, NY, USA: ACM. doi:10.1145/2591062.2591192.
- (2013). Kuhn, T., Forster, T., Braun, T., Gotzhein, R.: FERAL – framework for simulator coupling on requirements and architecture level. In: Proceedings of the 11th ACM-IEEE International Conference on Formal Methods and Models for System Design (MEMOCODE ‘13), Portland (Oregon), USA (2013) .
- Mehlhase, A., Jähnichen, S., Czwink, A., & Heinrichs, R. (1988). A Library and Scripting Language for Tool Independent Simulation Descriptions. In G. Marinucci (Ed.), Tecniche costruttive romane (Vol. 9952, pp. 622–638, Pubblicazioni dei gruppi archeologici d’italia, Vol. 32). Roma: Gruppo archeologico romano.
- Reif, J., Jeleniewski, T., & Fay, A. (uuuu-uuuu). An Approach to Automating the Generation of Process Simulation Sequences. In 2023 IEEE 28th International Conference on Emerging Technologies and Factory Automation (ETFA), Sinaia, Romania, 9/12/2023 – 9/15/2023 (pp. 1–4): IEEE. doi:10.1109/ETFA54631.2023.10275718.
- Schutzel, J., Peng, D., Uhrmacher, A. M., & Perrone, L. F. (2014 – 2014). Perspectives on languages for specifying simulation experiments. In 2014 Winter Simulation Conference – (WSC 2014), Savanah, GA, USA, 12/7/2014 – 12/10/2014 (pp. 2836–2847): IEEE. doi:10.1109/WSC.2014.7020125.
- van der Zee, D.-J., Tako, A., Robinson, S., Fishwick, P., & Rose, O. (2018?). PANEL: EDUCATION ON SIMULATION MODEL SIMPLIFICATION – BEYOND RULES OF THUMB. In 2018 Winter Simulation Conference (WSC), Gothenburg, Sweden, 12/9/2018 – 12/12/2018 (pp. 3987–4001). [Piscataway, NJ]: IEEE. doi:10.1109/WSC.2018.8632544.
- van Mierlo, S., Vangheluwe, H., & Denil, J. (2019). The Fundamentals of Domain-Specific Simulation Language Engineering. In 2019 Winter Simulation Conference (WSC), National Harbor, MD, USA, 12/8/2019 – 12/11/2019 (pp. 1482–1494, ACM Digital Library). [Erscheinungsort Nacht ermittelbar]: IEEE Press. doi:10.1109/WSC40007.2019.9004726.
- Wagner, G. (2016 – 2016). Introduction to simulation using JavaScript. In 2016 Winter Simulation Conference (WSC), Washington, DC, USA, 12/11/2016 – 12/14/2016 (pp. 148–162): IEEE. doi:10.1109/WSC.2016.7822086.
Related Posts

Microsoft AutoAdminLogon knacken und Admin Center rückgängig machen (27. Juli 2026) Borns IT- und Windows-Blog

Batteriehersteller Varta reicht mehrere Insolvenzanträge ein (24. Juli 2026) Borns IT- und Windows-Blog
