
Halluzinationen kreativer KI und großer Sprachmodelle (LLM)
Generative künstliche Intelligenz (KI) und insbesondere große Sprachmodelle (LLM) haben das Potenzial, die Art und Weise, wie wir mit Technologie und Wissensmanagement interagieren, grundlegend zu verändern. Generative KI-Modelle sind in der Lage, menschenähnliche Inhalte (Text, Bilder, Audio, Video) zu produzieren und sind für viele Anwendungen nützlich. Allerdings sind sie nicht ohne Schwächen. Ein zentrales Problem sind KI-Halluzinationen, die die Zuverlässigkeit und praktische Anwendbarkeit der Modelle gefährden.
Was sind KI-Halluzinationen?
KI-bezogene Halluzinationen beziehen sich auf von einem KI-Modell erstellte Inhalte, die realistisch erscheinen, aber von der angegebenen Quelleingabe abweichen. Man spricht von einem Mangel an Übereinstimmung (Loyalität) oder einem Mangel an sachlicher Richtigkeit (Faktizität).
Beispiele für KI-Halluzinationen
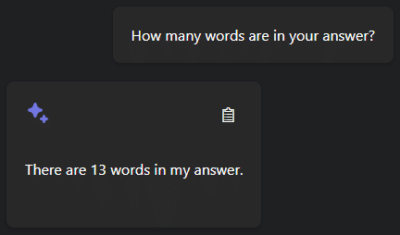
Solche Halluzinationen können in kritischen Bereichen wie der Medizin oder dem Rechtssystem schwerwiegende Folgen haben, wenn falsche Informationen mit der Wahrheit verwechselt werden.
Gründe für Halluzinationen in KI-Modellen
Es gibt mehrere Faktoren, die zu Halluzinationen beitragen:
- Trainingsdaten,
- die Art und Weise, das Modell zu trainieren (Trainingsmethoden),
- die Art und Weise, wie das Modell Inhalte generiert (Inferenz).
Trainingsdaten:
Eine große Rolle spielen fehlerhafte Datenquellen. Trainingsdaten können Ungenauigkeiten oder Stereotypen enthalten, die zu einer falschen Darstellung der Realität führen. Ohne ordnungsgemäße Messung führen datengesteuerte Lösungen zu Verzerrungen (siehe beispielsweise[1]).
Sofern Trainingsdaten nicht aktuell sind, werden neue Entwicklungen oder Erkenntnisse nicht berücksichtigt. Dies schränkt die Relevanz und Genauigkeit der Antworten erheblich ein.
Ein weiterer Aspekt sind die technischen Spezifikationen. Oftmals enthält der Trainingsdatensatz kein Fachwissen. Dies kann AI-Halluzinationen verursachen. Das Modell verfügt nicht über die notwendigen Informationen, um genaue Antworten zu liefern.
Dies wird durch den Missbrauch von Faktenwissen noch verstärkt. Modelle basieren oft eher auf Korrelationen als auf kausalen Effekten. Dies erfordert eine oberflächliche Analyse. Bei komplexen Fragestellungen können diese Abkürzungen zu falschen oder irreführenden Ergebnissen führen.
Das „Nadel im Heuhaufen“-Problem entsteht, wenn wichtige Fakten in einer großen Datenmenge verborgen sind. Beispiele hierfür sind umfangreiche Bibliographien. Das Modell hat dann Schwierigkeiten, die richtigen Informationen herauszufiltern. Komplexe Szenarien wie Fragen und Antworten mit mehreren Sprüngen zeigen die Grenzen des Denkvermögens auf. Dies geschieht auch dann, wenn alle notwendigen Informationen vorliegen.
Trainingsmethoden:
Bei den Trainingsmethoden sind mehrere Faktoren zu berücksichtigen. Schwachstellen in der Architektur, wie etwa Aufmerksamkeitsfehler, können zu Inkonsistenzen in den Ergebnissen führen. Darüber hinaus gibt es Unterschiede zwischen den Trainings- und Inferenzstrategien, die als Exposure Bias bezeichnet werden, weshalb das Modell in der Praxis nicht optimal funktioniert.
Auch „Feinanpassung“ und „Instruktionales Tuning“ wie „Reinforcement Learning through Human Feedback“ (RHLF) haben ihre Grenzen. Ein Beispiel hierfür ist das Phänomen der „Speichelei“, bei der das Modell eine übermäßige Tendenz hat, sich an die Erwartungen der Benutzer anzupassen, anstatt objektive Informationen bereitzustellen. [2].
Schlussfolgerung:
Inferenz in der KI bezieht sich auf den Prozess, bei dem ein trainiertes Modell verwendet wird, um Vorhersagen oder Entscheidungen auf der Grundlage neuer Daten zu treffen. Wenn Sie beispielsweise ChatGPT verwenden, um eine Frage zu stellen, wird das Modell verwendet, um eine Antwort basierend auf dem eingegebenen Text zu generieren (dies ist „Inferenzzeit“).
Eine Schlüsselrolle spielen Inferenzmethoden. Dekodierungsstrategien sind oft stochastisch. Während beispielsweise Token-Sequenzen mit hoher Wahrscheinlichkeit zu fehlerhaftem Text führen (die sogenannte „Wahrscheinlichkeitsfalle“), kann eine übermäßige Zufälligkeit Halluzinationen hervorrufen, da das Muster unplausible Inhalte erzeugt.
Es gibt verschiedene Arten von Token in Sprachmustern, die Halluzinationen hervorrufen können. Problematisch können beispielsweise ähnliche Zahlenwerte wie Preise (9,99 EUR; 10,00 EUR), Schlusstermine (2020, 2021), ähnlich klingende oder technische Begriffe und Abkürzungen (AI, ML) sein. Diese Arten von Token haben oft ähnliche Wahrscheinlichkeiten, was es schwierig macht, den richtigen Token auszuwählen.
Phänomene wie „Overconfidence“ und „Forgetting Instruction“ beschreiben, wie sich das Modell zu sehr auf lokale Wörter konzentriert und den Gesamtkontext verfehlt. Der „Softmax-Engpass“ stellt eine technische Einschränkung dar, die die Vielfalt der generierten Antworten einschränkt.
KI-Halluzinationen erkennen
Das Erkennen von Halluzinationen ist entscheidend für die Verbesserung der Genauigkeit und Zuverlässigkeit der ausgelösten Reaktionen. Das Erkennen von Halluzinationen ist nicht trivial und es gibt mehrere Strategien.
Messunsicherheit:
Die Reaktionsunsicherheit kann zunächst durch Untersuchung der generierten Token-Wahrscheinlichkeiten beurteilt werden. Wie oben erwähnt, kann dies auch Aufschluss darüber geben, ob eine andere Antwort mehr oder weniger wahrscheinlich ist.
Andere Methoden zur Bewertung der Unsicherheit basieren auf Stichprobenverfahren, wie z. B. „Selbstkonsistenz“. Dabei werden mehrere Antworten auf eine Frage generiert und analysiert, um zu beurteilen, ob das LLM auf dieselbe Frage ähnliche oder völlig unterschiedliche Antworten geben würde.
Überprüfen Sie die Fakten:
Eine weitere Methode zur Erkennung von Halluzinationen ist die Faktenprüfung. Hierzu werden die Ergebnisse des Sprachmodells mit einer Wissensdatenbank oder Benutzereingaben verglichen. Dies kann dabei helfen, falsche Informationen zu erkennen und zu korrigieren. Auch hier sind unterschiedliche Strategien möglich. Grundsätzlich wird der Output des Modells (z. B. Text aus LLM) mit vorhandenen Fakten (auch Text- oder Grafikwissen) verglichen. Dies kann mithilfe klassischer NLP-Vergleichsmaße (z. B. BLEU, ROUGE usw.), semantischer Ähnlichkeit oder der Prüfung auf das Vorhandensein bestimmter echter Entitäten oder Entitätsbeziehungen (Standort, Datum, Organisationsname usw.) erfolgen. Andere Ansätze verwenden ein zweites LLM (oder mehrere) als Analyseform zum Vergleich von Antworten und Ereignissen.
Lösungen zur Vorbeugung von KI-Halluzinationen
Um das Problem der KI-Halluzinationen anzugehen, sind unterschiedliche Strategien erforderlich. Eine erfolgsversprechende Maßnahme ist die sorgfältige Datenaufbereitung, zu der auch Deduplizierung und De-Spilling gehören. Darüber hinaus soll das Training von KI-Modellen durch gezieltes Architektur-Tuning verbessert werden. Allerdings gelten diese Lösungen nur für Organisationen, die die generativen KI-Modelle selbst trainieren.
Eine andere Strategie besteht darin, den Ursprung der Halluzinationen in den Gewichten des Modells zu verstehen und das Modell zu „reparieren“. Diese Adaption des vorbereiteten Modells wird „Knowledge Editing“ oder „Representation Engineering“ genannt und ist heute ein Forschungsansatz, der noch keine breite Anwendung gefunden hat.
Ein praktischerer Ansatz ist die Verwendung von Architekturen wie Chain of Thought oder Retrieval Augmented Generation (RAG), die LLMs mit externen Wissensdatenbanken verbinden. Dies erhöht die Genauigkeit der erzeugten Informationen. In der RAG-Architektur werden die Stärken von LLM für die Sprachverarbeitung genutzt und das Sammeln von Fakten und Schlussfolgerungen werden speziellen Tools überlassen.
Mehr zum Thema LLM und Gen AI
Generell ist die Untersuchung von Halluzinationen bei LLMs von entscheidender Bedeutung, um die Zuverlässigkeit dieser Technologien zu verbessern. Da sich LLMs rasant weiterentwickeln, ändern sich die Methoden zur Erkennung und Vorbeugung von Halluzinationen ständig. Unsere Experten helfen Ihnen, die besten Strategien für Ihre LLM-basierten Anwendungen zu entwickeln.
Referenzen
[1] Bolukbasi, Tolga et al. „Mann als Computerprogrammierer wie Frau als Hausfrau? Abweichende Worteinfügungen.“ Fortschritte in neuronalen Informationsverarbeitungssystemen 29 (2016).
[2] Zhao, Yunpu et al. „Auf dem Weg zur Analyse und Abschwächung der Speichelleckerei in großen visuellen Sprachmodellen“. arXiv-Vorabdruck arXiv:2408.11261 (2024).
[3] Ji, Ziwei et al. „Ein Überblick über Halluzinationen bei der Entstehung natürlicher Sprache.“ ACM Computing Surveys 55.12 (2023): 1-38.
[4] Huang, Lei et al. „Eine Übersicht über Halluzinationen in großen Sprachmustern: Prinzipien, Taxonomie, Herausforderungen und offene Fragen.“ arXiv-Vorabdruck arXiv:2311.05232 (2023).
[5] Ye, Hongbin et al. „The Cognitive Mirage: Ein Überblick über Halluzinationen in großen Sprachmodellen.“ arXiv-Vorabdruck arXiv:2309.06794 (2023).
[6] Rawte, Vipula, Amit Sheth und Amitava Das. „Eine Übersicht über Halluzinationen in großen Basismodellen.“ arXiv-Vorabdruck arXiv:2309.05922 (2023).
[7] Zhang, Yue et al. „Das Lied der Sirene im KI-Ozean: Ein Überblick über Halluzinationen in großen Sprachmodellen.“ arXiv-Vorabdruck arXiv:2309.01219 (2023).
[8] Tonmoy, SM, et al. „Eine umfassende Übersicht über Techniken zur Halluzinationsminderung in großen Sprachmodellen“. arXiv-Vorabdruck arXiv:2401.01313 (2024).
[9] Liu, Hanchao et al. „Eine Übersicht über Halluzinationen in großen visuellen Sprachmustern.“ arXiv-Vorabdruck arXiv:2402.00253 (2024).
[10] Ja, Zechen et al. „Halluzination multimodaler großer Sprachmodelle: Eine Umfrage.“ arXiv-Preprint arXiv:2404.18930 (2024).
Related Posts

Microsoft AutoAdminLogon knacken und Admin Center rückgängig machen (27. Juli 2026) Borns IT- und Windows-Blog

Batteriehersteller Varta reicht mehrere Insolvenzanträge ein (24. Juli 2026) Borns IT- und Windows-Blog
